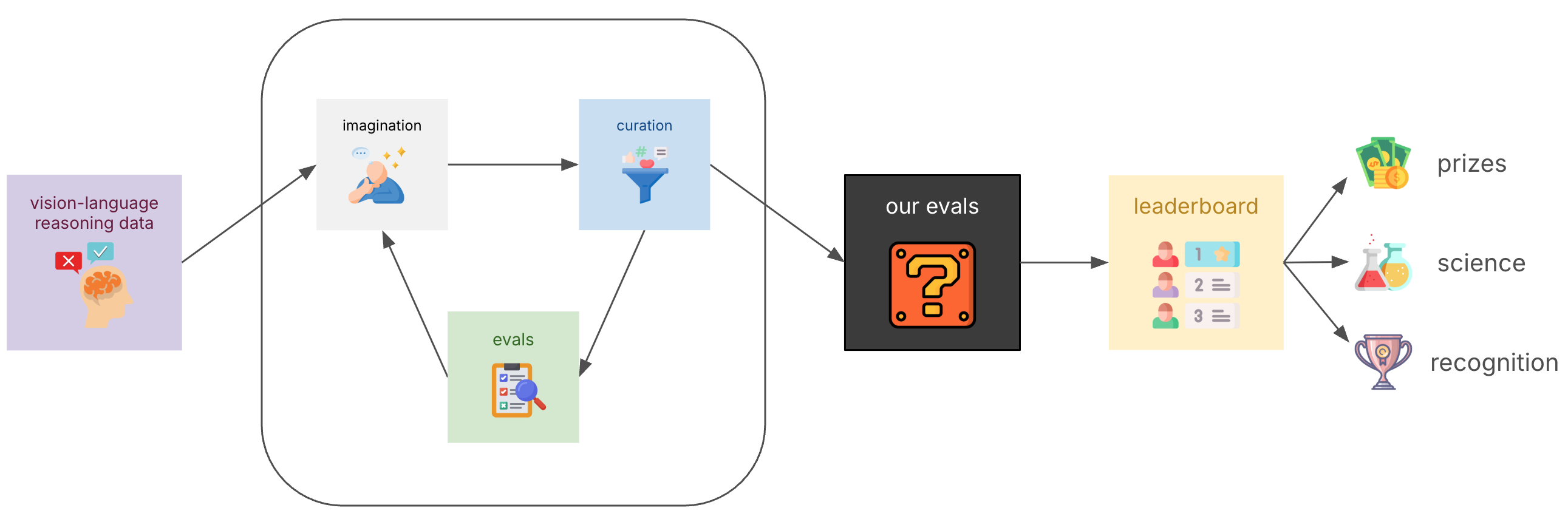
DCVLR (Data Curation for Vision-Language Reasoning) is a fully open-source effort to curate the best open reasoning datasets for VL models; it is a collaboration led by Oumi.ai and Lambda.ai, integrating an open-source community effort driven by collaborators from Stanford, MIT, NYU, UW, Cal Tech, AI2, University of Tuebingen, Tel Aviv University, and more.
Recent research (LIMA, LIMO) has shown that careful curation of a small dataset can really boost task performance; "A Handful of (Carefully Constructed and Curated) Examples is All You Need". Unfortunately, most datasets and data generation strategies unfortunately remain closed, even after model weights are open-sourced. Data generation efforts for vision-language reasoning trails language-only efforts. Therefore, rather than focusing solely on novel architectures or training techniques, DCVLR puts reproducible methods for data curation front and center.
DCVLR teams will curate approximately 10,000 data points using their own curation strategies. The most effective methods—as measured by a comprehensive combination of public and held-out benchmarks—will be showcased at NeurIPS, providing recognition for the often-underappreciated and understudied work. Our evaluation suite includes rigorous benchmarks such as VMCBench-DEV, LiveXiv, and OlympiadBench, ensuring that winning submissions demonstrate genuine improvements in vision-language reasoning capabilities.
Team signup is now live, with submissions opening very soon! What makes DCVLR particularly accessible is that curation strategies don't need to be novel. They can build upon existing published work, draw inspiration from established methodologies, or even apply existing techniques in creative new ways. The key requirements are reproducibility and scalability—we want strategies that the broader research community can understand, replicate, and build upon.
To provide concrete examples for team, the DCVLR organizers have prepared several baseline submissions. These baselines showcase two fundamental high-level strategies: synthesis and filtration. Synthesis baselines focus on generating new, partially or fully synthetic data points that enhance model training, while filtration baselines excel at identifying and selecting the most valuable subsets from existing large-scale datasets. Many successful approaches combine these strategies, and indeed, several of our baselines implicitly do so—for instance, some datasets we filter may contain synthetic elements from their original curation process.
Our methodology for these experiments involved fine-tuning Qwen 2.5 7B Instruct models on our curated datasets using Oumi's powerful training infrastructure, followed by comprehensive evaluation using the Oumi fork of VLMEvalKit. While we won't delve deeply into the training and evaluation procedures in this post—these are thoroughly covered in our DCVLR Starter Kit; we do want to clarify that we will not necessarily use the same model for our competition ranking.
Our results demonstrate that even relatively simple baseline curation strategies can yield impressive performance gains. Some of our straightforward baseline submissions already show substantial improvements over the base Qwen Instruct model on average, highlighting the transformative power of strategic data curation.
This comprehensive blog post accomplishes two main objectives. First, we'll provide detailed documentation of the baseline curation strategies we've developed, offering concrete examples and practical guidance for competition participants. Second, we'll explain our technical approaches to both synthesis (leveraging Oumi's capabilities) and filtration (utilizing our data-preproc package prepared for DCVLR), providing you with the knowledge and tools needed to implement your own successful curation strategies.
We've developed five distinct baseline curation strategies. Each baseline represents a different philosophy and methodology, from small-scale high-quality synthesis to large-scale strategic filtration. These baselines serve both as competitive submissions and as educational examples for participants to study and build upon.
Our synthesis strategies focus on generating new, contextually appropriate data points that address specific gaps or weaknesses in existing datasets. These approaches typically produce smaller, more targeted datasets that can deliver outsized performance improvements.
Dataset Size: 1,000 samples
Approach: Synthesis
Strategy Reference: Research Paper
Model: oumi-ai/dcvlr_qwen2_5_s1.1_VL
Dataset: oumi-ai/s1-vis-mid-resize
The S1.1 VL strategy represents our most focused synthesis approach, creating a carefully curated collection of 1,000 high-quality vision-language pairs. This method emphasizes quality over quantity, generating synthetic data points that specifically target common reasoning gaps in existing datasets. The approach is particularly effective for creating challenging visual reasoning scenarios that require multi-step thinking and complex visual understanding.
Dataset Size: 1,000 samples
Approach: Synthesis
Strategy Reference: Research Paper
Model: oumi-ai/dcvlr_qwen2_5_vl_7b_limo_vis
Dataset: oumi-ai/limo-vis-mid-resize
The LIMO VL strategy takes a language-informed approach to multimodal data synthesis, leveraging advanced language models to create contextually rich and semantically coherent vision-language pairs. This method excels at producing data that requires sophisticated reasoning across both visual and textual modalities, making it particularly valuable for tasks requiring deep cross-modal understanding.
Our filtration strategies focus on intelligently selecting the most valuable subsets from large-scale existing datasets. These approaches typically work with larger volumes of candidate data, applying sophisticated filtering criteria to identify samples that will most effectively improve model performance.
Dataset Size: 2,000 samples
Approach: Filtration
Strategy Reference: GitHub Repository
Model: oumi-ai/dcvlr_qwen2_5_vl_7b_multimodal_open_r1
Dataset: oumi-ai/multimodal-open-r1-8192-filtered-mid-ic
The Multimodal Open R1 strategy applies sophisticated reasoning-focused filters to identify data points that specifically enhance multimodal reasoning capabilities. This approach builds upon the Open R1 methodology, which emphasizes the importance of reasoning chains and step-by-step problem solving in multimodal contexts. The filtering process prioritizes samples that demonstrate clear reasoning patterns and complex visual-textual interactions.
Dataset Size: 10,000 samples
Approach: Filtration
Strategy Reference: Research Paper
Model: oumi-ai/dcvlr_qwen2_5_vl_7b_MM_MathInstruct
Dataset: oumi-ai/MM-MathInstruct-to-r1-format-filtered
The MM MathInstruct strategy focuses on mathematical reasoning capabilities, filtering from a large corpus of mathematical instruction data to identify the most effective samples for enhancing quantitative reasoning in vision-language models. This approach is particularly valuable for applications requiring numerical analysis, geometric reasoning, and mathematical problem-solving across visual and textual domains.
Dataset Size: 10,000 samples
Approach: Filtration
Strategy Reference: Research Paper
Model: oumi-ai/dcvlr_qwen2_5_vl_7b_walton_multimodal_cold_start
Dataset: oumi-ai/walton-multimodal-cold-start-r1-format
The Walton Multimodal Cold Start strategy addresses the challenging problem of bootstrap learning in multimodal contexts. This filtration approach identifies data points that are particularly effective for models learning from limited initial knowledge, focusing on foundational concepts and clear examples that can serve as strong starting points for more complex reasoning development.
One of the most powerful aspects of the Oumi framework is its comprehensive support for data synthesis, particularly for creating high-quality vision-language datasets. Our synthesis pipeline consists of two main stages: generating image synthesis code and executing that code to create the final dataset with rendered images. This approach allows for unprecedented flexibility and control over the synthetic data generation process.
The first stage of our synthesis pipeline uses synthesize_images_vllm.py, a script to generate Python code that can create contextually appropriate images for each data sample. This innovative approach leverages large language models to understand the requirements of each sample and generate corresponding visualization code.
The workflow begins by loading a HuggingFace dataset containing text-only samples or samples requiring visual components. The system then uses a configurable LLM (we use Claude Sonnet via an API call) to analyze each sample and generate Python code that will create an appropriate image. This code typically uses libraries like matplotlib, PIL, or other visualization tools to create diagrams, charts, geometric figures, or other visual representations that complement the textual content.
The script offers extensive configuration options, including model selection, GPU memory utilization settings, generation temperature control, and adaptive batch sizing based on model requirements.
Oumi's synthesis framework provides several key advantages that make it particularly well-suited for DCVLR competition needs. The framework's modular architecture allows for seamless integration of multiple data sources—from HuggingFace datasets to custom document collections—while its sophisticated attribute generation system leverages LLM-powered conversations to create contextually rich synthetic content. The production-ready scalability ensures that teams can generate large-scale datasets efficiently, with batch processing capabilities and memory-efficient sampling strategies that handle massive source datasets. Perhaps most importantly for competition participants, Oumi's configuration-driven YAML approach makes complex synthesis pipelines both reproducible and easily shareable, addressing the competition's core emphasis on reproducible data curation methods. The framework's comprehensive quality control mechanisms, including built-in post-processing pipelines and attribute validation, help ensure that synthetic data meets the high standards required for effective vision-language model training.
The second stage utilizes the run_image_synthesis.py script to execute the generated code and create the final dataset with rendered images. This stage transforms the generated code artifacts into actual visual content and assembles them into a properly structured HuggingFace dataset. The system automatically fixes common compatibility issues, adds missing imports, and ensures that visualization libraries work correctly in the execution environment.
Effective data filtration is crucial for maximizing the impact of existing large-scale datasets. Our filtration approach leverages the data-preproc toolkit, a specialized utility designed for comprehensive dataset preprocessing with particular strength in preparing data for large language model and vision-language model fine-tuning.
Data-preproc provides a modular, configuration-driven approach to dataset processing that supports multiple data types and preprocessing strategies. The framework excels in handling text completion datasets, instruction-following datasets, chat templates, and crucially for our purposes, multimodal datasets containing both visual and textual components.
The toolkit's strength lies in its comprehensive preprocessing capabilities, which include advanced deduplication algorithms, sophisticated filtering mechanisms, dataset schema transformations, and robust multimodal processing support. The system uses a YAML-based configuration approach that makes complex preprocessing pipelines both reproducible and easily shareable across research teams.
Our filtration pipeline leverages the data-preproc framework's comprehensive processor system, which follows a modular, configuration-driven approach that enables sophisticated dataset transformations while preserving data integrity. The framework's strength lies in its sequential processor pipeline where each stage receives the output of the previous stage, allowing for progressively refined filtering and transformation. Our DCVLR sample configuration demonstrates this power through a carefully orchestrated six-stage filtration process:
Stage 1: Image Count Filtering uses the image_count_filter processor to ensure dataset consistency by removing samples with zero images or multiple images, keeping only single-image samples that match our vision-language reasoning requirements. This initial stage prevents downstream processing issues and ensures uniform data structure.
Stage 2: Image Transformation applies the image_transform processor to resize oversized images down to 768px maximum while preserving aspect ratios, optimizing memory usage and training efficiency without losing visual information quality. This standardization is crucial for consistent model input processing.
Stage 3: Text Toxicity Filtering employs the text_toxicity_filter processor with Detoxify models to identify and remove harmful content across multiple toxicity categories (toxicity, severe_toxicity, obscene, threat, insult, identity_attack). Using a conservative 0.9 threshold ensures only clearly appropriate content passes through, maintaining dataset safety standards.
Stage 4: Image Toxicity Filtering utilizes the image_toxicity_filter processor with CLIP-based detection to identify and remove inappropriate visual content, including NSFW material and potential underage risks. The conservative 0.6 threshold for both categories ensures comprehensive safety filtering of visual content.
Stage 5: Token Length and Quality Filtering applies the hf_filter processor to remove examples that are too short (under 200 tokens) or too long (over 13,500 tokens), while also validating image integrity and minimum dimensions. This ensures content has sufficient substance for meaningful training while fitting within model context windows.
Stage 6: Advanced Deduplication uses the deduplicator processor with combined fuzzy and n-gram methods to eliminate duplicate and highly similar content both within the dataset and against external benchmark datasets (OlympiadBench, VMCBench, LiveXiv-VLMEvalKit). This critical stage prevents data leakage and ensures evaluation integrity with a 98% similarity threshold and 15-gram analysis for semantic similarity detection.
| Model/Strategy | VMCBench-DEV | OlympiadBench | LiveXivVQA | LiveXivTQA | Dataset Size | |---|---|---|---|---|---| | Baseline Models | | Qwen 2.5 7B Instruct | 79.1% | 13.2% | 75.1% | 58.0% | - | | Claude Sonnet3 / GPT-4V4 | 81.3% | 18.0% | 75.4% | 83.5% | - | | DCVLR Baseline Strategies | | Walton Multimodal Cold Start | 78.7% | 13.1% | 70.0% | 79.8% | 10,000 | | MM MathInstruct | 80.0% | 7.1% | 73.8% | 57.7% | 10,000 | | Multimodal Open R1 | 77.1% | 9.7% | 73.4% | 66.7% | 2,000 | | S1.1 VL | 78.8% | 10.2% | 72.5% | 56.6% | 1,000 | | LIMO VL | 79.1% | 10.8% | 72.7% | 57.2% | 1,000 |
³ Claude Sonnet results for VMCBench-DEV, LiveXivVQA, and LiveXivTQA
⁴ GPT-4V results for OlympiadBench
Our baseline curation strategies demonstrate the substantial impact that strategic data curation can have on vision-language model performance, even with relatively modest dataset sizes. The Walton Multimodal Cold Start strategy, trained on just 10,000 carefully filtered samples, achieves particularly noteworthy results that highlight both the promise and challenges of data-centric approaches to model improvement.
The most striking result is the 37.6% relative improvement (from 58.0% to 79.8%) on LiveXivTQA, representing a substantial gain in the model's ability to answer complex academic questions based on arXiv papers. This improvement brings the fine-tuned model remarkably close to the performance of Claude Sonnet, demonstrating that strategic curation can help smaller, open models compete with state-of-the-art proprietary systems on specific reasoning tasks.
However, the results also reveal the nuanced nature of transfer learning in vision-language models. While LiveXivTQA performance soared, the model showed modest declines on VMCBench-DEV (79.1% to 78.7%) and more significant regression on LiveXivVQA (75.1% to 70.0%). This pattern suggests that the Walton strategy's focus on bootstrap learning and foundational concepts particularly benefits text-heavy reasoning tasks, while potentially over-specializing away from visual comprehension tasks that require different reasoning patterns.
The OlympiadBench results remain consistently challenging across all approaches, with both the baseline Qwen model and our fine-tuned version achieving only around 13% accuracy. This benchmark appears to require reasoning capabilities that transcend what current data curation strategies can address, representing a significant opportunity for future research in both synthetic data generation and more sophisticated filtration techniques that can identify truly challenging mathematical reasoning exemplars.
Now that you have a comprehensive understanding of our baseline curation strategies and the powerful tools available through Oumi and data-preproc, you're well-equipped to develop your own innovative approaches to vision-language data curation. The techniques we've demonstrated—from sophisticated synthesis pipelines to intelligent filtration strategies—represent just the beginning of what's possible in this exciting field.
The beauty of the DCVLR competition lies in its accessibility and openness. You don't need to invent entirely new methodologies to make meaningful contributions. Instead, you can build upon the foundation we've established, combining different approaches, refining existing techniques, or applying proven methods to new domains or datasets. The key is to focus on reproducibility, scalability, and effectiveness as measured by our comprehensive evaluation benchmarks.
Ready to join the competition? Team signup is now live, and we encourage you to form diverse, collaborative teams that can tackle the challenge from multiple perspectives. Whether you're interested in pushing the boundaries of synthetic data generation, developing novel filtration criteria, or exploring hybrid approaches that combine the best of both strategies, there's a place for your contribution in DCVLR.
Connect with the community! Join our Discord server for ongoing discussions, team building opportunities, and technical support. The DCVLR community is collaborative and supportive, and we're excited to see the innovative approaches that emerge from the collective creativity of participants worldwide.
Author: Benjamin Feuer